I finally parted with my 7-year old MacBook Air for a new WFH setup consisting of
- Macbook Pro M1
- 2 x 24″ wide monitors
- USB-C hub
I added a 10-in-1 USB-C hub as my “dock” to expand my ports. Essentially I require a USB-A for my wireless keyboard set (7 year old also), RJ45 for occasional networking and extra display ports for the dual extended monitors.
My original intention is to just have “one port” connected to my MBP as am I used to the “docking” model, so all the other connectors are served through the hub including USB-C PD and the dual displays. However the hub does not support DisplayLink, so it can only mirror the output and I still have to have an extra HDMI cable connected directly to my MBP. Boo…
UnnaturalScrollWheels
The first obvious discomfort is that Apple decided that it is natural for the mouse wheel should roll in the same direction as the trackpad. Not that it’s wrong, but I usually use the trackpad with Mac but the keyboard and mouse for Windows so my scroll direction is messed up. System Preferences allows me to reverse the scroll, but any setting affects both the trackpad and mouse wheel simultaneously.
Luckily I’m usually not the only one with these problems, and UnnaturalScrollWheels solves this gracefully.
brew install --cask unnaturalscrollwheels
Karabiner Elements
Next are the modifier keys. In Mac-world we have Control, Option and Command, whereas Windows have Ctrl, WinKey and Alt. Even then the Control works in different ways where Copy is Cmd+C vs Ctrl-C. For me because I’ve been using both in home and work I’m able to “code-switch” on both keyboards instead of mapping on to the other.
By setting my Citrix Viewer preferences I was able to get close to the Windows keyboard mapping, but Alt is still on WinKey and the left WinKey is forced to the right WinKey. System Preferences allows me to remap modifiers by input device but I still could not use my left WinKey for my commonly-used keystrokes like Win-E, Win-R with one hand.
 Citrix Viewer options
Citrix Viewer options
With Karabiner-Elements I was able to remap the right WinKey to the left and push the Alt back to where it was. Finally I can do Ctrl-Alt-Del with peace.
brew install --cask karabiner-elements
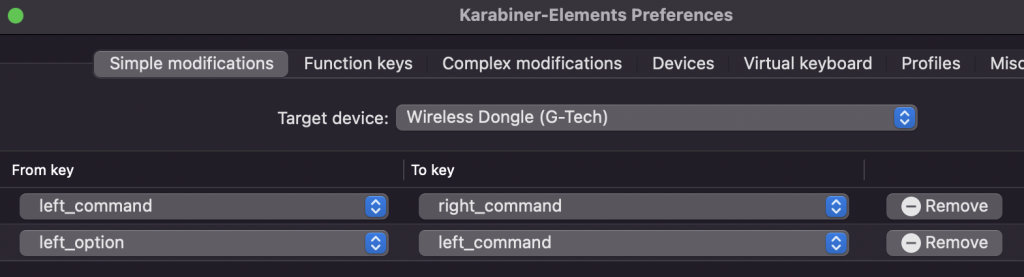 Karabiner configuration
Karabiner configuration
I also noticed that Karabiner can remap mouse clicks, including the middle click on the scroll-wheel. However it did not detect my wheel-scroll, so it was not able to replace UnnaturalScrollWheels.
Bonus Hint: Ctrl-Space for autocomplete may be by default mapped to Spotlight Search or Input Source change (I use multiple input languages) so they may need to be disabled/remapped in System Preferences > Keyboard > Shortcuts.
Bonus Problem: Alt-Tab in Citrix activates app switcher in Mac instead of inside remote Windows. I can still switch with Win-Tab, which is not as bad as Right-WinKey. Karabiner has “complex modifications” that can import rules from the web that seems to support this but I suspect I’ll still need to edit the rules to target an input. Another adventure for another time.
DisplayPlacer
My new monitors were placed above my MBP, giving me a triple-screen (the MBP screen was too big to waste). I decided to have Citrix Viewer span across the dual monitor giving me a dual screen, while my Mac activities remain on the MBP screen.
 Triple T
Triple T
Several issues:
- Stretching Citrix Viewer across two displays
In MacOS mission control, “Displays have separate spaces”. With that enabled, a window can only appear in one of the screens. Sure, Citrix Viewer has an View option to “Use all Displays in Full Screen” but that replaces all 3 displays I have, instead of 2.
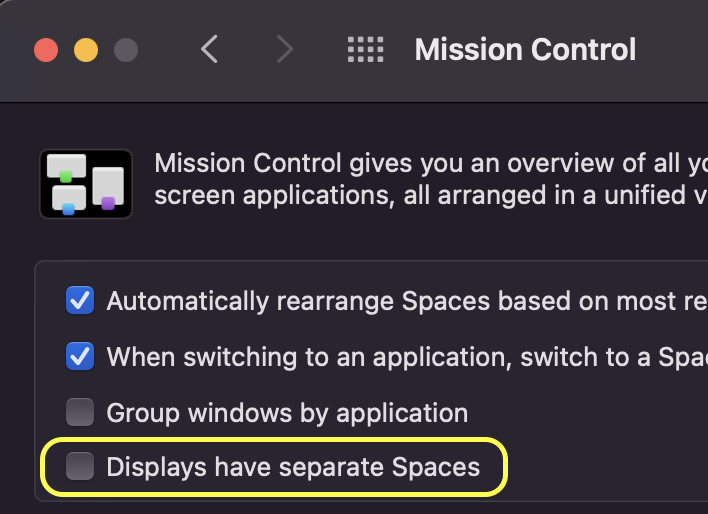 I happily disabled it…
I happily disabled it…
- Multiple extended displays with same model
Every time I come back to my workstation (either after a break or the next morning), the monitors and MBP are in sleep mode (which is good). But when I log in again, the MacOS reconnects to the displays and often gets them mixed up. I have to go back to System Preferences to swap the two monitor position each time.
There seem to be no way to consistently force one to be recognized as either one. I tried swapping the HDMI connection or turning them on in sequence, it turns out wrong most of the time.
https://apple.stackexchange.com/questions/49913/is-it-possible-to-get-os-x-to-remember-my-screen-arrangement
After a few days I got really sick of it and decided to fix it. Luckily for displayplacer, I was able to use a command to restore the display layout. On top of that I was able to align my MBP to the real center as in Display Preferences my dragging was not so accurate. (This is relevant to #3)
brew tap jakehilborn/jakehilborn && brew install displayplacer
displayplacer list
displayplacer "id:7F4AE512-B46E-4BDD-B537-4A2915732ADD res:1512x982 scaling:on origin:(0,0) degree:0" "id:EFE602E0-11AF-4FA7-8091-5756E196A81E res:1920x1080 scaling:off origin:(-960,-1080) degree:0" "id:EFE602E0-11AF-4FA7-B26F-A0E49098A77D res:1920x1080 scaling:off origin:(960,-1080) degree:0"
3. Lost window positions and size
After waking the MBP and monitors, not only the display layouts were gone, the windows that were on the extend displays got thrown back to the primary monitor as well. I have to re-position and resize the window each time. So, what if I can script the window position and size back, as well as run the displayplacer together with a global shortcut key? Mac Automator to the rescue!
Automating displayplacer was straightforward, I used “Run Shell Script” task and pasted the output from displayplacer list , the only caveat was to specify the full path as I have brew-ed it. I try to brew where available so I can manage versions, and uninstall it without wondering if I can drag applications to the Bin or I need an uninstaller.
/opt/homebrew/bin/displayplacer "id:7F4AE512-B46E-4BDD-B537-4A2915732ADD res:1512x982 scaling:on origin:(0,0) degree:0" "id:EFE602E0-11AF-4FA7-8091-5756E196A81E res:1920x1080 scaling:off origin:(-960,-1080) degree:0" "id:EFE602E0-11AF-4FA7-B26F-A0E49098A77D res:1920x1080 scaling:off origin:(960,-1080) degree:0"
The window stuff was trickier. I felt AppleScript could do it, but the basic “tell application to set bounds” didn’t work. Ultimately what worked for me was to go through System Events, and have commands to set the position and size separately. Also I discovered “window 1” was the little floating menu at the top so my intended target is “window 2”.
on run {input, parameters}
tell application "System Events" to tell application process "Citrix Viewer"
set position of window 2 to {-960, -1080}
set size of window 2 to {3840, 1080}
end tell
return input
end run
Still that wasn’t enough. When I try to set a global shortcut on it, it required permission on whatever app was in the foreground. It does not make sense nor practical to grant every app this access, so an extra workaround to extract the script was required.
do shell script "osascript -e 'tell application \"SetCitrixViewerBounds\" to activate'"
Finally, It works!